How one experiment can lead to 70 different conclusions
-
 Een MRI-scanner op het Donders Instituut (niet betrokken bij de Nature-studie). Foto: Rein Wieringa
Een MRI-scanner op het Donders Instituut (niet betrokken bij de Nature-studie). Foto: Rein Wieringa
A large neuroimaging study published in Nature has created quite a stir. It seems that the analytical flexibility that researchers have can have a major impact on the conclusions that they draw from an experiment.
It sounds like a joke for science nerds: What happens when you ask seventy brain researchers to draw conclusions from the same dataset? They won’t agree! In reality, however, this is not a bad joke, but the findings of an article published last month in the leading science journal Nature.
The study has caused a lot of controversy among scientists because it touches on the replication crisis in the social and medical sciences. In recent years, many startling research results (such as ‘bilingual people can concentrate better’ or ‘red wine is good for your health’) have not been confirmed in repeat studies, demonstrating the need for repeat experiments and reliable methods of analysis.
Gambling game
The new Nature study now shows that the reliability of analysis methods in brain research is also inadequate. The authors, led by PhD student Rotem Botvinik-Nezer of Tel Aviv University, asked 70 research groups worldwide to analyse the same dataset. They had to answer a simple question: Does the measured brain activity provide evidence for each of nine hypotheses?
The experiment itself was simple: 108 subjects could either make or lose money by playing a type of gambling game while placed in MRI scanners. The hypotheses related to what happens in the brain during such a task. For example, losing money causes increased activity in the amygdala, the part of the brain that plays a role in emotions.
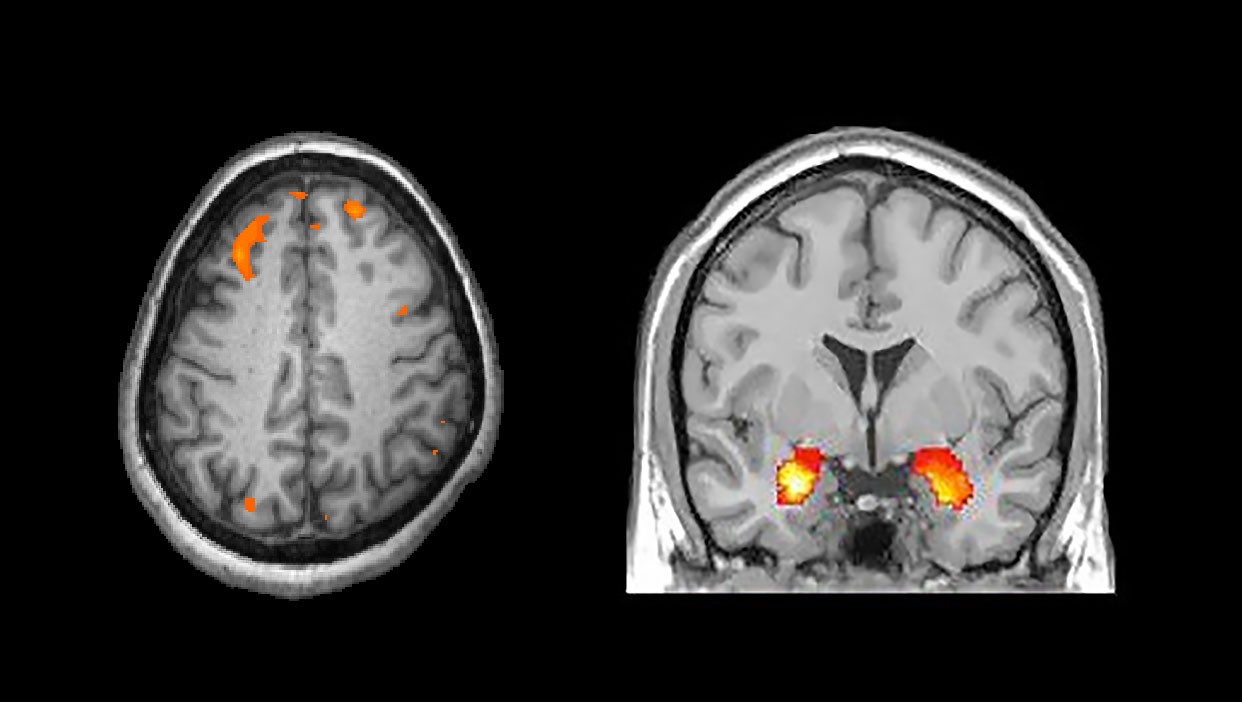
There was sizeable variation in the results from the seventy participating groups. The groups were in partial agreement about only four of the nine hypotheses. One hypothesis was considered proven by more than 84 percent of the researchers, and three were rejected by nearly everyone (almost 95 percent). Opinions were divided about the other five hypotheses.
‘Landmark study’
The considerable amount of disagreement doesn’t surprise methodologist John Ioannidis, who responded to us by email. Ioannidis is Professor of Medical Sciences at Stanford University and has published several influential articles on research methodology and the replication crisis. His most famous publication, Why most published research findings are false, from 2005, is the most quoted article in the medical journal PLoS Medicine.
Ioannidis calls the recent Nature article a ‘landmark study’. ‘With MRI data, you have to make a lot of decisions during the analysis process,’ he writes in his email. ‘As a result, even seasoned researchers can arrive at different conclusions based on the same dataset.’
These decisions relate to such questions as: When has a subject moved too much to provide meaningful data? How big is the brain surface for which you combine the measurements? At what statistical threshold do you describe brain activity as ‘significant’? No two groups made the exact same decisions, according to the Nature article.

The Stapel scandal
Does that mean that also most neuroscience research findings are false? No, laughs Xiangzhen Kong of the Max Planck Institute in Nijmegen. He took part in one of the seventy analyses and is a co-author of the Nature publication. ‘There is simply no “best” method of analysis for this kind of complex data,’ he explains over the phone.
He sees the study primarily as an example of how you can improve transparency and the reproducibility of brain research. ‘For example, it should become more routine for researchers to share all their data and analysis code.’ Together with the other Nature authors, he also advocates that researchers record in advance exactly what analysis steps they plan to take, a kind of ‘pre-registration’.
It continues to be difficult to monitor published results. Neuroscientific articles often contain only brief descriptions of the research methods, making it almost impossible to repeat experiments and analyses exactly. It might also make it easier to commit fraud – just think of the Stapel scandal.
Kong finds it unsurprising that there is ambiguity about more than half of the hypotheses. In his view, this means that the brain signal in those cases was probably just around the detection limit. It’s like trying to figure out whether or not someone is saying something to you at a noisy party.
‘The solution is to think more carefully about how you set up experiments, such as including more subjects. That’s why I’m also in favour of greater collaboration between research groups – it gives you a bigger sample size and enables you to draw more reliable conclusions.’
‘Neuroscientists can make mistakes. That’s not a ground-breaking conclusion.’
Psychologist Fred Hasselman agrees. Too small a group size was often a problem in past neuroimaging studies. ‘But this dataset involved 108 participants. This suggests that other causes may also have played a role.’ Hasselman, an Assistant Professor in Social Sciences, coordinated a large study two years ago in which 28 psychological experiments were each repeated 60 times in order to test the reliability of their results.
Large individual differences between subjects could be one of those other causes, says Hasselman. ‘These make it difficult to interpret neuro-imaging results, as a research group from the Donders Institute has recently shown. And we know from behavioural research conducted in Nijmegen that there is indeed considerable variation in behaviour in the task that subjects performed in the Nature experiment.’

Not convinced
Not everyone is equally impressed by the Nature study. ‘As far as I’m concerned, the differences in outcomes show that some groups made incorrect assumptions in their analyses,’ says Prof. Ivan Toni of the Donders Centre for Cognitive Neuroimaging. He was not involved in the study.
These types of assumptions include which part of the measurement signal is ‘noise’, caused, for example, by subjects moving their head in the scanner. If you don’t take that into account, you can draw incorrect conclusions. Toni: ‘Neuroscientists can make mistakes, but that’s not the ground-breaking conclusion I expected from a Nature article.’
Toni doesn’t believe it makes sense to have each research result systematically re-analysed by multiple groups, as the Nature authors suggest. ‘First of all, the scientific process is already doing this to some degree through the peer-review system.’
Secondly, he believes it is more efficient to spend the limited resources on properly training researchers. ‘That way, they learn how to design robust analyses and they are also better at detecting errors in the analyses carried out by their peers.’



